

“Tikkoun Sofrim” (Hebrew for “Scribal Correction”) is a joint French-Israeli project to integrate the wisdom of the masses to digitalize ancient manuscripts using Handwritten Text-Recognition (HTR).
Training computers to read ancient Hebrew manuscripts using automatic reading is a complex process. In the first stage, the system analyses the manuscript layout and trains kraken, a deep learning engine for automatic reading that supports HTR. This powerful engine supports script detection and multiscript recognition; Right-to-Left, BiDi, and Top-to-Bottom scripts; ALTO, abbyXML, and hOCR output; word bounding boxes and character cuts; a public repository of model files; dynamic recognition model architectures and GPU acceleration; a clean public API. And all this with an open source licence.
The Human Touch
The kraken engine has proven to do the job quite well, with an error rate of less than 10% and sometimes even as low as 3% on a letter level. But that’s not good enough.
When it comes to definitively transcribing texts that are to pass on the wisdom of the ancient world for today – and tomorrow — the error rate has to be 0. The Tikkoun Sofrim project was born out of the need to generate open and freely available digital text with undisputed accuracy in a reliable, efficient and cost-effective way.
Leveraging the Wisdom of the Masses
Tikkoun Sofrim combines the power of automatic Handwritten Text-Recognition and the naked eye – through crowdsourcing. Via the Tikkoun Sofrim website, registered as well as anonymous users check the automated transcription and manually correct mistakes. The corrections also serve to improve the kraken HTR reading engine as it learns from the inputted revisions.
“Our goal is to combine state-of-the-art technology that knows how to convert the manuscript into digital text, and the wisdom of users, or rather, the curiosity of the users, that can correct its mistakes,” say Prof. Tsvi Kuflik and Dr. Moshe Lavee of the Digital Humanities Program at Haifa University who lead the project on the Israeli side. “Students of ancient texts, whether they are scholars or not, have the ability to correct artificial intelligence when it makes a mistake.”
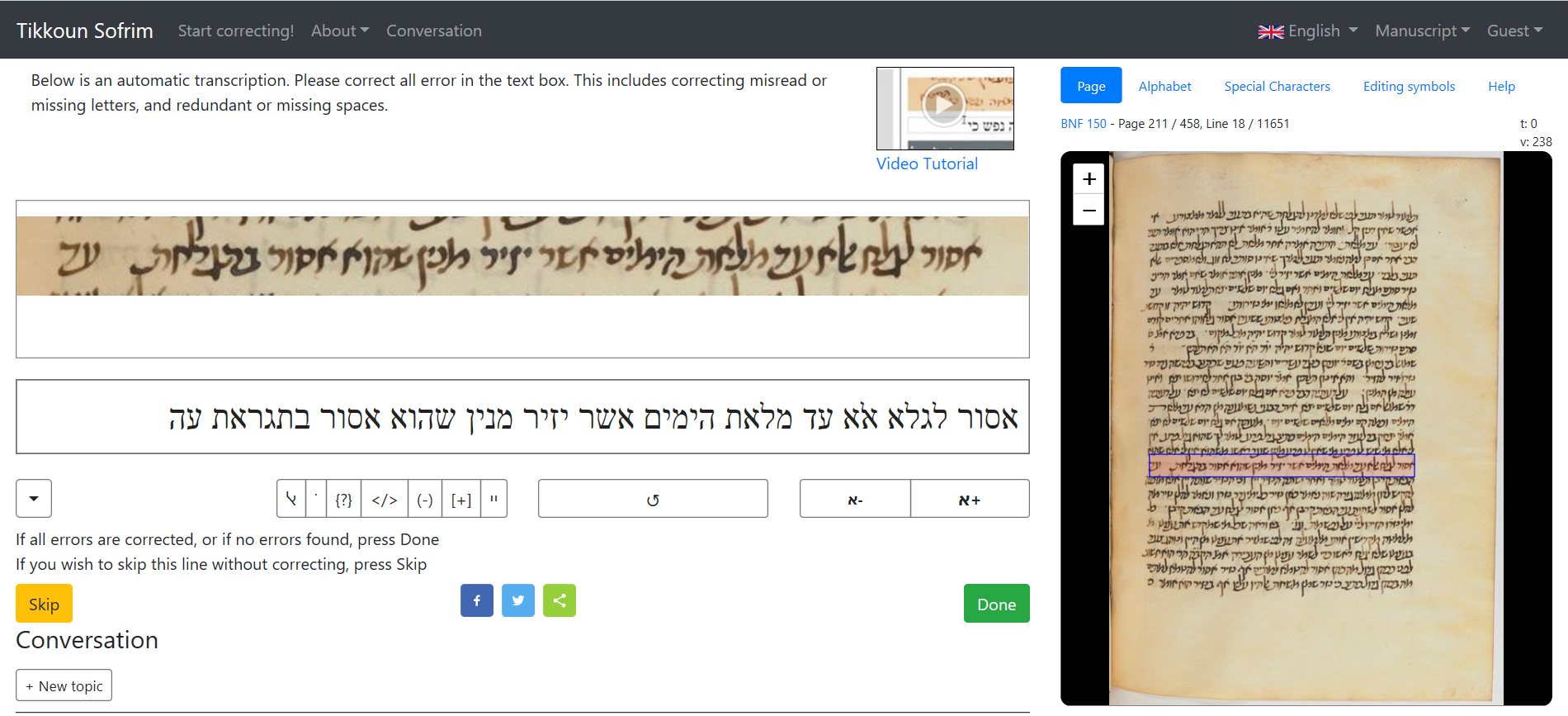
The web interface opens the image of the manuscript alongside a work area with the digital version. The work area includes important tools and shortcuts to annotations, common symbols, and other characteristics.
The project is a joint French-Israeli project, developed by the École Pratique des Hautes Études (EPHE), Université PSL, the department of Information Systems at Haifa University and the National Library of Israel. The project is supported by the French Ministry of Higher Education and Research, the French Ministry of Foreign Affairs and the Israeli Ministry of Science.
The project has made significant progress – from proof of concept to a crowdsourcing pilot and full production. As of late 2019, four complete manuscripts have been read by kraken and are undergoing crowdsourcing revisions by approximately 375 registered users. The crowdsource portal went online in February 2019 and as of December about half of the manuscripts have been revised and corrected with more than 90,000 line correction strikes. For such seemingly tedious work, the pace is pretty fast: an average of 12 lines in 8 minutes.
Advancing the Humanities… One Line at a Time
According to Prof. Daniel Stoekl Ben Ezra of the EPHE, this project represents a true breakthrough in the study of ancient Hebrew manuscripts, or ancient manuscripts in any language or script for that matter. “Once images of these manuscripts are transcribed into searchable text, researchers can use the text mining software kits and other tools available to them to enhance their research. This will allow reading thousands, indeed millions, of pages in a short time and provide information based on queries researchers can pose. And it is incredibly exciting that the public, in Israel and abroad, are our partner in this.”
Bringing the Past to the Future
RENATER and IUCC, the high-speed R&E networks of France and Israel are essential enablers of this project. Vast numbers of high-resolution images scans require capacity, speed and redundancy.
And while the Tikkoun Sofrim project is motivated by the wisdom of the past, its sights are on the future. Currently the system is based on a download of the HTR scanned image to a local server that feeds the web portal. Many libraries, museums and manuscript repositories do not allow download mechanisms and require real time viewing from their servers. Just to allow the real time processing and viewing the millions of pages of the currently ca. 80,000 digitised Hebrew manuscripts hosted at the Israel National Library require the capacity and speed that only R&E networks can offer.
![]()

![]()
![]()





